Enterprise data warehouses as a source of data for simulation
 June 26, 2022
June 26, 2022
 3016 words
3016 words
 15 minutes to read
15 minutes to read

Organizations juggle 400 unique data sources for business intelligence and analytics on average (IBM Corporation, 2021). While more data is typically better for business growth, handling hundreds of different data sources can become a nightmare without specialized tools.
One of the solutions that businesses can use to streamline data management is data warehousing software. Data warehouses can significantly simplify data handling from numerous distinct data sources. They typically support data sources in the cloud and on-premises and can provide seamless access to them via a centralized interface.

Businesses can use data warehouses for a variety of purposes. A few areas that can immensely benefit from data warehouses include machine learning, data science, marketing, and simulation.
This blog will introduce readers to the benefits of data warehousing software for simulation purposes and explain why it can be a great data source for studies. The benefits we will outline apply to many other use cases, but we will cover a few points specific to simulation.
What is a data warehouse?
A data warehouse is a system that serves as a central repository of structured data. Data warehouses allow teams to access data from disparate sources in a centralized, efficient, and effective way.
Data warehouses are closely related to enterprise data warehouses. The two concepts are overall synonymous, though some businesses might put a distinction between them. Enterprise data warehouses encompass an organization’s data stores across all of its functions and departments. A data warehouse, in contrast, might imply an entire organization or its specific part.
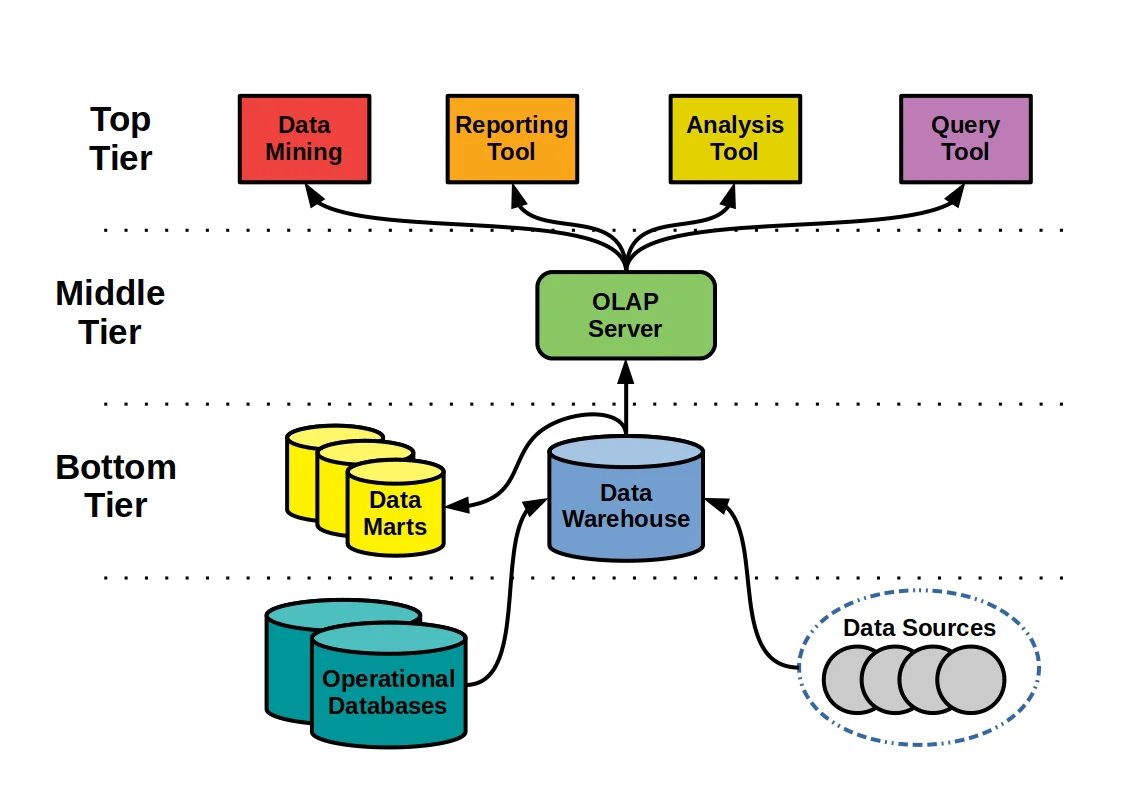
Data warehouses have multi-level architectures that help them perform their functions. A typical data warehouse has three tiers (IBM Cloud Education, March 5 2020a):
- Top tier. The top tier is usually a front end that allows users to retrieve and analyze their business data. Data warehouses typically enable users to join data from different sources, apply transformations to it, generate graphs and explanations, and share their findings with their teammates.
- Middle tier. The middle tier typically consists of a high-speed analytics engine that enables users to fetch data. The middle tier can operate on an OLAP (online analytical processing) server to process large volumes of data.
- Bottom tier. The bottom tier is the database server that loads data from its data sources. The bottom tier typically relies on ETL (Extract, Transform, Load) or ELT (Extract, Load, Transform) routines to load and process data.
Data in data warehouses can be current (real-time) or historical. Existing data can be used for forecasting and decision-making in production. In contrast, historical data can be used for tasks like long-term performance assessment or the training of machine learning models. Historical data is usually much more extensive in volume than current data.
Current data or data that is accessed frequently is typically stored in fast, low-latency storage devices, like solid-state drives (SSDs). Alternatively, whenever necessary, essential data can be fetched from remote storage to local storage so that the end-user doesn’t have to download it from a remote source every time they need it.
Historical data, in contrast, is usually stored in cheaper storage, like cloud storage. Historical data is accessed infrequently and doesn’t need to be available on-demand. Consequently, data warehouses can efficiently process petabytes of historical data to enable high-speed data exploration and analysis.
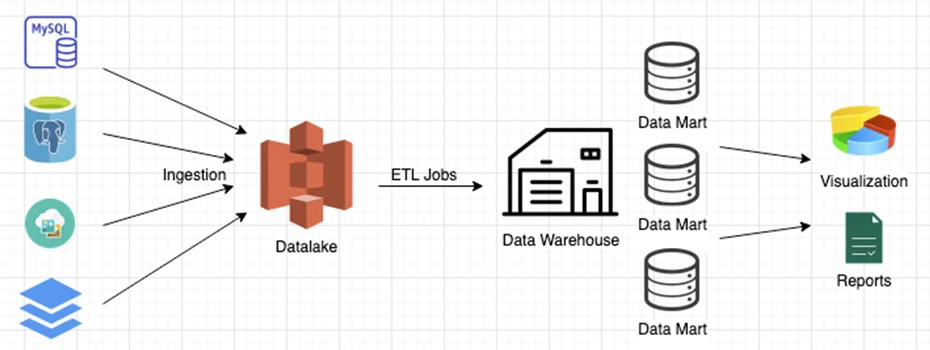
Data warehouses vs data lakes vs data marts vs databases
Data warehouses, data lakes, data marts, and databases are closely related – so much so that they are sometimes confused with each other. However, it’s essential to realize that they have very different purposes (IBM Cloud Education, March 5, 2020b). Here’s what each of these technologies means and how it is applied practically across an organization.
“If you think of a Data Mart as a store of bottled water – cleansed and packaged and structured for easy consumption – the Data Lake is a large body of water in a more natural state. The contents of the Data Lake stream in from a source to fill the lake, and various users of the lake can come to examine, dive in, or take samples.”
— James Dixon, founder of Pentaho Corp, who coined the term “Data Lake” in 2010.
- Data warehouse. A data warehouse collects data from multiple heterogeneous sources into a single repository. Data warehouses usually require data to be in a tabular format compatible with SQL queries. Data in data warehouses need to be structured following some schema to ensure consistency across data from different sources.
- Data lake. A data lake is a data warehouse without a predefined schema. Data in data lakes can be semi-structured or completely unstructured. Like big data analytics or machine learning, some applications do not require structured data and can work with data lakes. With little to no preprocessing, data lakes can provide faster access to the data stored in them.
- Data mart. A data mart is a data warehouse that contains data relating to a specific business function or department. Because data marts are smaller than data warehouses, they can provide more focused analytics at a higher speed.
- Database. Databases are designed for transaction processing and fast queries, whereas data warehouses are designed for analytics. Databases serve specific software applications and focus on real-time data, while data warehouses combine real-time and historical data. A database can also serve as a data source for a data warehouse.
Figure 2-Data Warehouses vs Data Lakes vs Data Marts vs Databases
“The complexity of this raw data means that there is room for something that curates the data into a more manageable structure (as well as reducing the considerable volume of data.) The Data Lake shouldn’t be accessed directly very much. Because the data is raw, you need a lot of skill to make any sense of it. You have relatively few people who work in the Data Lake, as they uncover generally useful views of data in the lake, they can create a number of data marts each of which has a specific model for a single bounded context.”
—Martin Fowler, Data Blogger at ThoughtWorks: Data Lakes may become Data Swamps
Why do businesses need data warehousing solutions?
Data sources for data warehouses can be highly diverse and include:
- Readings from IoT devices.
- Statistics from CRM systems like Salesforce CRM.
- Data from analytics tools like Google Analytics.
- Data from surveys.
Data collected from these sources can be stored in various locations, like on-premises data centers or cloud storage. More specific examples of possible storage locations include:
- Local files on an on-premises computer.
- SQL databases on an on-premises data center.
- Google Cloud buckets.
- Amazon S3 object storage.
- Snowflake data cloud.
Ideally, all business data would come from a single data source. This process would make accessing data extremely easy because employees would only need one storage solution to fetch the necessary data. However, in practice, businesses often store their data across dozens and dozens of storage locations.
Without a specialized solution that would make accessing data from different sources easy, businesses would have to tackle challenges like these:
- Teams would have to fetch data from their data sources individually. For example, they would need to fetch data in Google Cloud from the Google Cloud Console, data in S3 from the S3 console, and data in an SQL database via tools like the Microsoft SQL Server. If the number of data sources reached hundreds, accessing data would become a chore for employees because they would need to use a massive number of tools.
- Teams need to address disparities in data from different sources to ensure that it is compatible with internal IT or simulation workflows. Data collected at different times and coming from different data sources could have inconsistent timestamp formatting, disparities in data types, or may have been preprocessed to varying degrees.
- Teams would need to clean data from each data source. They would need to manually examine the data for missing values and outliers and discard junk data for each available data source.
- Teams would not have an easy way of sharing the results of their work with each other. Without a centralized tool for work-sharing, employees might use email or their personal cloud storage accounts to share data. One of the issues is that without standardization and external control, employees might end up with different versions of duplicate data that might be incompatible. Employees might also struggle to figure out which specific dataset they are supposed to be using.
Data warehouses can solve these problems by providing unified data access, cleaning, and analysis environment. Let us explore exactly how in the next section.
Benefits of data warehouses for simulation
The benefits of data warehouses for simulation are centered around improving the accessibility of data. As far as simulation modeling is concerned, here are the benefits that enterprise data warehouses provide.
Centralized access to different data sources
Simulation engineers can access and fetch research data from a centralized interface with a data warehousing solution. Rather than code a data fetching routine for each existing data source or use personal software tools, they can access all their data from one place.
Data warehousing suites can support dozens of data sources and data formats. Azure Synapse Analytics, as an example, supports data stores and formats like Azure Blob Storage, Amazon Redshift, Google BigQuery, Amazon S3, SFTP, and Snowflake (Microsoft, Jun 16, 2022). Simulation engineers can point to the data source for each supported data format so that the data warehouse knows where to collect the data. Engineers can also define a schema for their data sources to ensure that the data is converted to the required structure upon retrieval.
Data warehouses also allow simulation engineers to apply consistent transformations across different datasets to ensure they can interoperate. The transformations can be automated to bring each new data point to the expected format for simulation use cases. Thus, data warehouses can also be set up to not perform any transformations on the data and retrieve it raw.
With all that in mind, data warehouses only require an initial setup. Once simulation engineers define where the data comes from and how it should be processed, their data warehousing solution will automatically perform data fetching and transformation.
Accelerated large-scale analytics
Data warehousing suites can significantly simplify and accelerate data exploration and analytics for simulation teams, especially at large scales. Data warehouses parallelize data fetching and transformations, allowing simulation teams to save time working on substantial data sets.
Data warehouses sometimes come with built-in tools for data visualization and statistical analysis to simplify data exploration. Data warehouses might also support programming languages like Python or Scala to enable custom exploration functions for particular use cases.
Enterprise data warehouses are often compatible with third-party business intelligence and analytics platforms. These can be alternatives to built-in analytics tools for cases when a team prefers a specific data analytics service.
Finally, because data warehouses can bring data into a consistent form, simulation engineers might be able to develop a single routine for the statistical analysis of all their data sources. If engineers expect data in a specific format, they can create a statistical test suite that would work with simulation data regardless of its source. At the very least, this should be possible for most use cases. After initial setup, this could significantly simplify and accelerate input modeling for simulation across each of its four phases (Nodematic, Oct 16, 2021).
Simplified sharing of work across teams
And as the final benefit that we wanted to mention, data warehouses streamline the sharing of work within and between simulation teams.
Simulation engineers can maintain a centralized research data repository with a data warehousing solution. Rather than manage separate repositories that might be outdated or be inconsistent with each other, simulation engineers can access the latest version of the work from their data warehouse dashboard.
Whenever simulation engineers need data, they will know that they can access it from their data warehouse without guesswork. Rather than ask around to figure out where the data is, engineers will know that the default place to look is the data warehouse.
Vasilakis, et al. (2004, December) outlined the advantages of employing data warehousing techniques for storing and analyzing simulation output data. They demonstrate the problem and the proposed solutions when evaluating patient flow through hospital departments. Quaddus and Intrapairot (2001) assessed the impact of management policies on the diffusion of data warehouse in a large commercial bank in Thailand. For this purpose a system dynamics-based decision support system was developed and analyzed. The qualitative model first formulated seven management policies associated with the existing state of the data warehouse diffusion at the bank. A subsequent quantitative model simulated the impact of the seven identified management policies. The findings discovered that two prevailing policies of ‘increase level of training’ and ‘decrease training delay’ would speed up the data warehouse diffusion significantly.
Finally, Wong, et al. (2021) transformed a massive volume of raw networking data collected by WTFast about latency associated with player interaction on the Gamers Private Network (GPN). The data was structured, cleaned, and populated into a special-purpose data warehouse. Significant analysis was executed by applying machine learning, neural net technologies, and business intelligence tools. The results demonstrate the ability to predict and quantify changes in the network and demonstrate the benefits gained from the use of a GPN for users when connected to an online game session. Thus, we can discern from these investigations that some fascinating examples of the integration of data warehousing and simulation.
Cloud vs on-premises data warehousing solutions
Data warehouses are available as managed cloud services or self-hosted, on-premises solutions. Simulation teams should consider both options because they have distinct advantages and disadvantages, as described below.
Cloud data warehouses – like Amazon Redshift, (Amazon Web Services, n.d.), Google BigQuery, (Google Cloud, n.d.), or Azure Synapse Analytics (Microsoft, 2022) – are managed by third parties and are located off-site. With cloud data warehouses, businesses don’t need to dedicate space to on-premises data centers because data center management is outsourced to the cloud service provider. Besides, cloud data warehouses are scalable and can provide computing resources on-demand with no changes in a business’s infrastructure. Compliance is also simplified because cloud providers follow privacy regulations and apply consistent data protection measures across their services.
On-premises data warehouses are more expensive to deploy and require management. Scalability can also be an issue because businesses need to expand their data centers to grow their warehousing capabilities physically. On the other hand, on-premises data warehouses provide more control over the data stored in them, which can be beneficial for industries with stringent data security or data privacy regulations.
Simulation teams should assess whether they can afford to have their data stored away in a third party’s data center to get started. If this is possible, then cloud data warehouses would probably be the optimal solution for most cases. Even though cloud data warehouses take away some degree of control, they can drastically simplify the deployment and expansion of data storage infrastructure.
Next steps
Remember, the usefulness of data warehouses isn’t limited to just simulation. Data warehouses can streamline processes and functions across an organization, like business intelligence, data science, or machine learning workloads.
With that in mind, businesses should have a broader viewpoint when considering data warehousing solutions for simulation use. They should also think about incorporating the rest of their infrastructure into data warehousing. Enterprise data warehouses can significantly accelerate data-heavy workloads, so businesses that rely on data in their day-to-day operations should consider using data warehousing software.
If you are interested in exploring this topic further, we would recommend some free/inexpensive courses:
- Coursera: Getting Started with Data Warehousing and BI Analytics
- Coursera: Modernizing Data Lakes and Data Warehouses with Google Cloud
- Coursera: Modern Data Warehouse Analytics in Microsoft Azure.
A subsequent approach to learning about data warehousing and simulation is to gain access to playing Emerge2Maturity (Mannino, et al., 2021, p. 77):
“The simulation game, Emerge2Maturity, addresses learning challenges faced by students as they experience development over time, determine capabilities to balance costs and benefits for consistency with an organization’s strategy, observe organizational learning effects on costs and benefits, and gain awareness of the impact of external events. To support decision-making by players and address these learning challenges, Emerge2Maturity uses two novel models: the Capability Assessment Model for choices about data sources subject to budget and resource constraints and the Configuration Model for transition among decision-making phases involving constraint levels, learning effects, and external events. Simulation in each phase and phase summaries provide opportunities for players to reflect about their progress in developing a data warehouse.”
References:
Amazon Web Services. (n.d.). Amazon Redshift: Accelerate your time to insights with fast, easy, and secure cloud data warehousing at scale. AWS. https://aws.amazon.com/redshift/
Google Cloud. (n.d.). BigQuery. https://cloud.google.com/bigquery
IBM Corporation. (2021). How to choose the right data warehouse for AI. IBM. https://www.ibm.com/downloads/cas/QK7MQ7YY
IBM Cloud Education. (March 5 2020a). Data warehouse architecture. IBM. https://www.ibm.com/cloud/learn/data-warehouse#toc-data-wareh-n_j6aLQQ
IBM Cloud Education. (March 5, 2020b). Data warehouse vs. database, data lake, and data mart. IBM. https://www.ibm.com/cloud/learn/data-warehouse#toc-data-wareh-86wFunzB
Mannino, M. V., Khojah, M., & Gregg, D. G. (2021). Emerge2Maturity: A Simulation Game for Data Warehouse Maturity Concepts. Journal of Information Systems Education, 32(2), 77-91.
Microsoft. (2022). Azure Synapse Analytics. Azure. https://azure.microsoft.com/en-us/services/synapse-analytics/
Microsoft. (Jun 16, 2022). Azure Data Factory and Azure Synapse Analytics. Microsoft. https://docs.microsoft.com/en-us/azure/data-factory/connector-overview
Nodematic. (Oct 16, 2021). Input modeling as a foundation for simulation. Software Delivery Simulator. https://softwaresim.com/blog/input-modeling-as-a-foundation-for-simulation/
Quaddus, M., & Intrapairot, A. (2001). Management policies and the diffusion of data warehouse: a case study using system dynamics-based decision support system. Decision Support Systems, 31(2), 223-240.
Vasilakis, C., El-Darzi, E., & Chountas, P. (2004, December). A data warehouse environment for storing and analyzing simulation output data. In Proceedings of the 2004 Winter Simulation Conference, 2004. (Vol. 1). IEEE.
Wong, A., Chiu, C. Y., Hains, G., Humphrey, J., Fuhrmann, H., Khmelevsky, Y., & Mazur, C. (2021). Gamers Private Network Performance Forecasting. From Raw Data to the Data Warehouse with Machine Learning and Neural Nets. arXiv preprint arXiv:2107.00998.


