Common mistakes in simulation modeling and how to avoid them
 November 4, 2022
November 4, 2022
 3247 words
3247 words
 16 minutes to read
16 minutes to read

Simulation studies can be beneficial for gaining insight into real-world phenomena or even designing new products or systems. However, the success of simulation can be highly reliant on careful planning and implementation.
Simulation studies not only need to be implemented correctly from a technical point of view, but they must also be error-free. They must be able to perform their business objectives. To ensure these goals, simulation teams need to deeply understand their study’s purpose and be ready to scrutinize the outcomes they achieve carefully.
However, such activity is easier said than done, especially for inexperienced teams. Realizing the importance of proper simulation design is a great start, but how can teams put all the theories into practice?
To help teams start simulating efficiently and effectively, we will look at 5 common mistakes (and their solutions) in simulation modeling through the prism of software delivery.
5 common mistakes in simulation modeling
Below, we’ll talk about the five most common mistakes in simulation modeling described in the study “Typical Pitfalls of Simulation Modeling - Lessons Learned from Armed Forces and Business.” While this study emphasizes simulation in business and the armed forces, these mistakes could happen in any simulation study regardless of the industry involved.
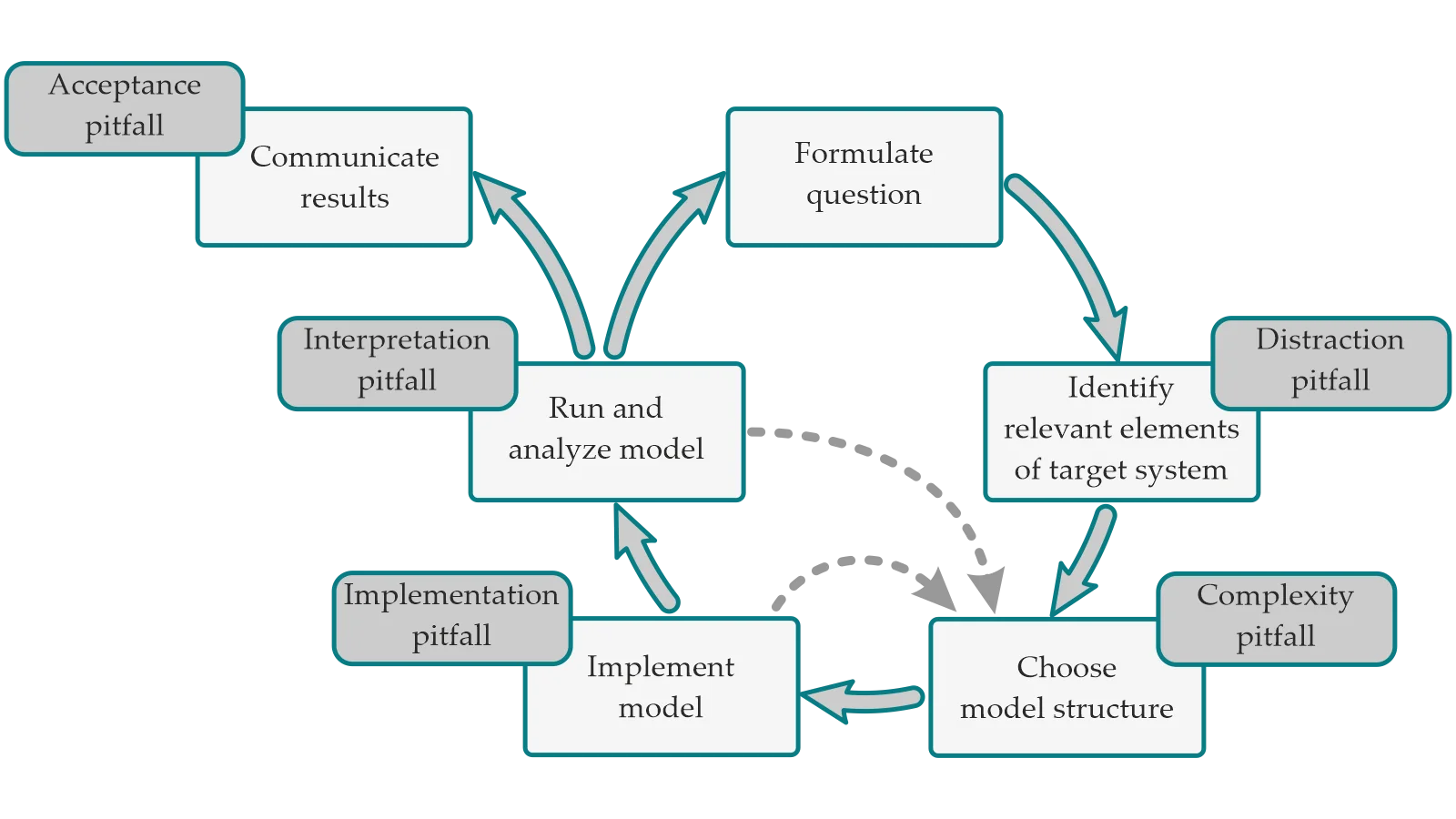
The five mistakes mentioned in the study are as follows (Barth, et al., 2012):
- Distraction pitfall.
- Complexity pitfall.
- Implementation pitfall.
- Interpretation pitfall.
- Acceptance pitfall.
Let’s now take a look at each of these pitfalls more in-depth.
Distraction pitfall

The distraction pitfall happens when the simulation team constantly expands the scope of the simulation, “distracting” itself from the core objective of the simulation project.
Let’s take testing automation [TA1] in software development to demonstrate the distraction pitfall. Suppose that the focus of our study is assessing the effect of testing automation on the speed of API tests. Because API endpoints can share many components and can be easily standardized, API tests can be easily automated to a large degree, bringing significant time savings to CI/CD.
While working on API test automation, simulation engineers might attempt to extend the scope of their study to include other types of tests. But there is a potential issue here – some tests can have problematic or even impossible components to standardize and automate. This challenge means that findings from API test automation might not extend to other types of tests, leaving engineers no choice but to develop new rulesets and constraints for each additional class of software test. With every new test, the scope of the study would expand, making it costlier and more challenging to manage.
Why does the distraction pitfall happen? Some of the more common reasons for distraction in simulation include the following:
- Unclear simulation objective. Simulation teams might sometimes fail to develop a straightforward, targeted question for their simulation study. Without a specific goal to achieve, simulation engineers won’t know when they should stop adding new details to their simulations.
- Overconfidence. The simulation team might be overconfident in its capabilities and may attempt to tackle several questions at once. Larger models may be realizable. However, without clarity and proper planning, simulation projects can expand uncontrollably and cease being practical or manageable.
- Lack of confidence. Some teams might think their simulation study isn’t comprehensive or impactful enough. This situation can often be due to perceived pressure and professional expectations from other researchers, reviewers, or supervisors. Lack of confidence could result in simulation teams increasing the scope of their research beyond what they can actually do.
- Pressure from stakeholders. Stakeholders and third-party decision-makers typically don’t have technical knowledge of simulation. As a result, they might not have the intuition of what is and is not achievable and could come up with unmanageable objectives that cannot be met in one project.
Complexity pitfall

The complexity pitfall is when the simulation team builds a model that is too complex for the task it is designed to accomplish. Simulation teams might end up building models that are unnecessarily complex due to these two reasons:
- Attempts to tackle several issues at once. The researchers might try to answer several questions at once, increasing the complexity of the simulation. This challenge actually means that the complexity pitfall can be a consequence of the distraction pitfall. As simulation teams add more and more details to cover in their study, their simulation model will inevitably grow more complex.
- Overemphasis on realism. Simulation may get too complex if the researchers try to make their simulation model realistic. The problem with realism is that it requires researchers to consider a massive amount of tiny details that might not be relevant to the core objective of the study. Simulation models don’t need to represent reality down to its most minor aspects– they only need to be complex enough to meet the study’s goal.
For the first point, our previous example with API test automation fully applies to the complexity pitfall. As for the second point, an example of excessive realism would be if engineers tried to model the automation of different types of API endpoints separately. If the endpoints can all be automated to a similar degree, then adding extra detail to the model probably won’t bring significant improvements.
Making simulation models more complex than necessary can be extremely costly. Simulation studies might require more time to develop and manage as they become more complex. Additionally, overly complex models take more compute time, memory, and storage space. Finally, working on a complex simulation for weeks and then scraping it because it doesn’t work would waste the researchers’ time and a firm’s money.
Implementation pitfall

The implementation pitfall is when the simulation team chooses the wrong programming or software solution to implement the simulation. This pitfall often happens when the team is so eager to implement the model that it neglects to create a proper simulation plan first. While it might be tempting to start simulating immediately, teams need to begin by understanding what they will be simulating. At this stage, abstract simulation model plans can be extremely beneficial.
Why is it essential to have an abstract simulation model before implementation begins? The abstract simulation model can help simulation teams determine their study’s technical requirements and constraints.
According to Barth, et al., 2012, there are two main drivers for the implementation pitfall – the desire to deliver results fast and the desire to reduce costs. These two drivers can prompt researchers to build their simulations using existing systems or tools. While existing tools may work, they might not be easily adaptable to simulation because they had been designed for other purposes. Similarly, researchers might start simulating using a popular tool that’s not actually suitable for their study’s goals.
For example, simulation engineers might choose the Python programming language to develop their simulation models. Python is an excellent programming language for research because it’s easy to learn and has a wide range of libraries for scientific tasks. However, native Python can be quite slow compared to languages like Rust or C++. Specialized computation or machine learning libraries in Python can be fast because they are written in C++ or other high-performance languages under the hood, but native Python code is exceptionally slow.
Tempted by the advantages of Python, researchers might downplay its weak performance. At first, this may not even matter – but as the simulation model grows and the researchers start needing to run it repeatedly, they may discover that it takes a very long time for the runs to complete.
If the simulation study was clearly outlined from the get-go, researchers would have known that a lower-level language like C++ or Rust would have been a better choice for large volumes of data and complex models. Alternatively, they would have researched Python better to discover ways to write efficient code that runs adequately fast for their needs.
Interpretation pitfall

The interpretation pitfall occurs when researchers fail to analyze their model’s performance properly. Interpretation errors can happen due to the following mistakes:
- Failure to detect errors in the simulation model. Errors in simulation models are highly diverse and range from choosing the wrong probability distribution to incorrectly preprocessing data. For example, suppose engineers choose the normal distribution to model the time to commit new code to GitHub. In that case, there might be a very small probability of negative time, which is obviously impossible and unrealistic. Errors like these are fortunately and typically easy to detect because they can result in nonsensical or completely unexpected results.
- Neglect of validation. This error can happen when researchers take the output of their simulation model at face value. The goal of simulation validation, if the team didn’t know, is to ensure that the simulation performs its research and business goals. Simulation models can technically work even without validation, but only with validation can researchers ascertain that the model accurately represents the target system or it doesn’t contain hidden errors that drastically affect outcomes.
- Attempting to extend the results of the study beyond its original scope. Simulation models are simplified representations of real-world systems. They are purpose-built to simulate a specific system with sufficient accuracy. This implies that simulation insights typically cannot be used to draw conclusions outside the scope of the study. This point is related to the distraction pitfall because overconfidence in simulation results could lead to engineers trying to develop more comprehensive models in their domain. Again, our earlier example with API tests applies here – results from API testing automation won’t necessarily extend to other tests.
- Skepticism about simulation results. The expectations of researchers might affect their interpretation of simulation results. Suppose the simulation results are correct but don’t match expectations. In that case, researchers might start erroneously tweaking the model to align its output with their assumptions or personal beliefs.
The interpretation pitfall commonly happens when researchers lose their critical distance to the simulation project. Simply put, researchers commit interpretation errors when they fail to analyze simulation results objectively. This situation can occur due to a strong attachment to one’s work or biases in the study.
Acceptance pitfall

The acceptance pitfall happens when third-party decision makers reject the results of an otherwise correct and valid simulation study.
While the acceptance pitfall may happen for many reasons, simulation results are often rejected because the researchers fail to convince stakeholders that their conclusions are correct. A big part of this is the stakeholders’ assumptions– if the simulation results are drastically different from their expectations, stakeholders will likely resist the findings.
Opaque simulation models that are not easily understandable might struggle with acceptance too. If stakeholders can’t see how exactly the simulation model came to specific results, they are more likely to be skeptical about conclusions that don’t precisely match their expectations. These expectations may be completely wrong, but if the researchers fail to demonstrate that their results are correct convincingly, acceptance might be a massive challenge for them.
Because the acceptance pitfall happens at the end of a simulation study, it is possibly the costliest of all the five pitfalls we’ve discussed today. Rejection from stakeholders can nullify weeks and months of hard work. Not only that, but one failed simulation study might weaken the confidence of the stakeholders in the simulation, putting future studies at risk.
How to avoid mistakes in simulation studies
Simulation teams can avoid most of the significant mistakes in simulation modeling if they focus on preventing the five pitfalls we’ve just discussed. However, how can simulation engineers plan with these pitfalls in mind and design more value-driven, convincing, and cost-effective simulation studies?
To answer this question, let’s now look at the most effective ways of making simulations mistake-free.
Avoiding the distraction pitfall
The prevention of the distraction pitfall begins with clarity. Stakeholders should clearly communicate their expectations to simulation teams so that the latter can formulate a focused, narrow objective for their studies. Without effective communication, simulation teams cannot determine what’s relevant to their research and what is not (Bagrodia, 1996, December).
The simulation model should only represent the part of reality directly related to the study’s objective. Throughout the study, researchers should regularly check whether their simulation meets the original goal and whether it has deviated from it.
With all that said, researchers might discover important questions to answer throughout the study. What should they do if this happens?
In most cases, the correct thing to do would be to stay focused on the original question and avoid expanding the scope of the study. All the extra questions that researchers discover should be investigated in separate, dedicated studies. However, if the new findings are critical to the success of the current study, then including them might be the right thing to do.
Avoiding the complexity pitfall
To prevent the complexity pitfall, simulation teams should first realize that added complexity can exponentially increase simulation costs. Not only that, but complexity can be challenging to handle – so much so that it can put the success of the simulation study at risk.
The target system should be stripped down to the core logic and mechanisms that are absolutely necessary to achieve the simulation objective (Kurkowski, et al., 2005). Anything that does not contribute to the model should be thrown away. Simulation teams should also remember that 100% realism is often unnecessary and almost always unachievable – instead, models need only to achieve realism levels that are reasonable for the study’s goal.
As far as large projects are concerned, simulation teams should break them down into several smaller sub-projects that they can then tackle one by one. Smaller projects would allow teams to keep their projects simple and efficient because they would be able to achieve small but visible results quicker. Besides, they would not have to think about the interdependencies between different target system components.
Avoiding the implementation pitfall
The solution to the implementation pitfall is quite simple – the abstract plan of the simulation should dictate the details of its technical implementation, not the other way around. Based on the volume of data to be processed, the abstract plan can help researchers choose the most optimal technical implementation for the study (Williams and Ülgen, 2012).
Another thing that researchers should determine is whether or not they can reuse existing IT systems, like databases. Existing systems can help researchers reduce implementation costs, but there’s an important caveat here.
It may be tempting for simulation teams to reuse existing systems, but they should keep in mind that the data requirements of simulation models might make these systems inadequate. If we take existing databases as an example, they might not have sufficient performance to serve vast volumes of data. They might also not be easily adaptable to new data sources, meaning that building a new simulation-focused database might be more reasonable.
Involving subject matter experts in the planning phase can immensely help with avoiding the implementation pitfall as well. Subject matter experts can guide simulation engineers in areas like performance and scalability to help them develop faster and more cost-effective simulation implementations. Prototyping could further help simulation teams by allowing them to check technical assumptions in practice and identify potential bottlenecks and issues early on.
Avoiding the interpretation pitfall
The key to avoiding the interpretation pitfall lies in carefully analyzing simulation results. Researchers must find a plausible explanation for each aspect of their simulation model. They should also find alternative explanations for the results to double-check that their primary explanations make sense and are actually applicable to the model (Koivisto, 2017).
Involving third parties is also extremely important in the analysis stage. Because third parties are not involved in the study, they can better maintain their critical distance and aren’t as heavily affected by biases.
Speaking of critical distance, it is the essential factor in avoiding the interpretation pitfall. Personal biases, attachment to the project, or overconfidence in one’s work can make researchers less alert. A healthy dose of self-skepticism and constant double-checking can help simulation teams maintain their critical distance from the simulation study.
Avoiding the acceptance pitfall
There are three keys to avoiding the acceptance pitfall (Sadowski, 1989, October):
- Early involvement of stakeholders in the study. The early involvement of stakeholders in the simulation study is perhaps the best way to avoid issues with acceptance. By involving stakeholders in the study earlier on, simulation teams can allow stakeholders to have a decisive say in the design of the simulation study. Not only can stakeholders help engineers define assumptions about the target process, but they will also be more likely to trust simulation results because they had direct participation in the study setup.
- Anticipation of objections from stakeholders. Simulation engineers should try to anticipate objections from stakeholders and come up with plausible explanations for them beforehand. Preparation can also help simulation engineers better understand their results or even identify and fix hidden mistakes in their conclusions.
- Non-technical, simple explanations. Simulation teams should avoid excessively mathematical explanations or technical terms in their presentation whenever possible. Simple, layman’s terms are much more effective at conveying results to non-technical businesspeople. Rather than focus on the math, the researchers should emphasize the intuition and the business value behind simulation results.
If we were to identify a common denominator between these three points, it would be as follows – the key to avoiding acceptance issues is gaining the trust of stakeholders. The stakeholders need to be able to trust the simulation to have enough confidence to accept it.
Simulation teams shouldn’t just focus on the “what” of their study –the raw simulation results and the metrics that the model achieved. Demystifying the “why” and “how” behind the simulation model is critical too – stakeholders need to understand the reasoning behind simulation conclusions.
Besides understanding, stakeholders should also be able to see the business value of simulation. Simply put, the simulation should show how the stakeholders can reduce operational costs or increase revenues. After all, as far as software delivery is concerned, most simulations are going to be serving some business goal.
Next steps
If we were to summarize the points we’ve discussed above, the two keys to successful simulation studies are clarity and critical distance.

- Simulation teams should have clear questions to answer in the study, while stakeholders should clearly understand why the study has come to specific conclusions.
- Simulation engineers should not take their findings at face value and should deeply validate them from all conceivable angles.
By maintaining clarity and critical distance, simulation teams can design successful models that not only are technical works of art but can also bring real benefits in business settings.
[TA1] The article “How Testing Automation Can Improve Software Delivery” could be linked from here.
References:
Bagrodia, R. L. (1996, December). Perils and pitfalls of parallel discrete-event simulation. In Proceedings Winter Simulation Conference, 136-143, IEEE.
Barth, R., Matthias M., and Spitzner, J. (2012). “Typical pitfalls of simulation modeling: lessons learned from armed forces and business.” The Journal of Artificial Societies and Social Simulation, 15(2), Article 5.
Koivisto, M. (2017). Pitfalls in modeling and simulation. Procedia Computer Science, 119, 8-15.
Kurkowski, S., Camp, T., & Colagrosso, M. (2005). MANET simulation studies: the incredibles. ACM SIGMOBILE Mobile Computing and Communications Review, 9(4), 50-61.
Sadowski, R. (1989, October). The simulation process: avoiding the problems and pitfalls. In Proceedings of the 21st conference on Winter simulation, 72-79.
Williams, E. J., Ülgen, O. M., (2012). Pitfalls in managing a simulation project, In Proceedings of the 2012 Winter Simulation Conference (WSC), 1-8, doi: 10.1109/WSC.2012.6464983.


