Combining the strengths of simulation and machine learning
 December 7, 2023
December 7, 2023
 2205 words
2205 words
 11 minutes to read
11 minutes to read

Based on mathematics and statistics, simulation and machine learning are powerful techniques that can help us better understand the world around us and build better IT systems. Machine learning and simulation differ drastically and perform different goals.
Despite their differences, simulation, and machine learning don’t have to be used in isolation – they can be combined to achieve much better results than either method alone. However, to understand how exactly the combination of ML and simulation might work, we need to understand what they are and what they aren’t.
Below, let’s explore the basic concepts of simulation and machine learning and see at a glance how they may be combined to improve research and obtain better IT systems.
Machine Learning vs Simulation – What’s the Difference?
Machine learning and simulation both heavily rely on mathematics. Both leverage calculus, probability theory, statistics, and linear algebra to varying degrees to achieve their goals. But even though the roots of machine learning and simulation are essentially the same, the two techniques have vastly different capabilities, goals, and use cases.
What is simulation?
Simulation is inherently process-centric. In a simulation, researchers have an in-depth understanding of how a system works, and their goal is to observe what would happen if you fed some input data to a simulated system. In simulation, the goal is to see what happens given a specific input. Von Rueden, et al., (2020, p. 5) describe the process framework for simulation
“Simulation comprises the two phases
1. model generation, and
2. model application, where the focus often is on the second phase, in which an earlier identified deductive model is used in order to create simulation results. The components of this phase are the simulation model, input parameters, a numerical method, and the simulation result. It describes the unfolding of local interactions from a compactly represented initial model into an expanded data space.”
Strictly speaking, inputs aren’t precisely known in simulation modeling. In technical terms, this means that simulation involves some degree of uncertainty. To address this uncertainty, researchers usually assume the probability distribution of the inputs based on observation, industry knowledge, or intuition. Once a distribution and its parameters are chosen, researchers randomly sample data points from that distribution and feed them into the simulation model. Based on thousands and thousands of inputs and corresponding outputs, researchers can conclude the behavior of various systems under different conditions.
Simulations are used for various purposes, including simulation of particle physics, fluid dynamics, manufacturing lines, customer queues, and even software delivery pipelines. With simulation, we can get a quantitative sense of how small changes can affect the efficiency of manufacturer lines, service speed in customer queues, or the durability of some novel material. All these use cases are united by one key characteristic – researchers know or at least have assumptions about how real-world systems work, and they want to see how the system will behave in different conditions.
To an extent, we know how fluids work, how energy transfer occurs in rigid bodies, and how our manufacturing pipelines operate. Simulations can capture the real world down to minor details when necessary or stay at a high level when we need to analyze just the general flow of components throughout a system. It’s precisely thanks to our knowledge of processes that we can simulate car crashes and assess how changes in our fiscal policies can affect macroeconomic metrics like inflation or unemployment.
What is machine learning?
In contrast to simulation, machine learning is data-centric. Machine learning is concerned with finding and exploiting relationships in data without necessarily understanding how exactly different variables interact and affect each other. Von Rueden, et al., (2020, p. 4) describe the process framework for ML:
“Machine Learning consists of two phases:
1. model generation, and
2. model application, where the focus is usually made on the first phase, in which an inductive model is learned from data. The components of this phase are the training data, a hypothesis set, a learning algorithm, and a final hypothesis. It describes the finding of patterns in an initially large data space, which are finally represented in a condensed form by the final hypothesis.”
In machine learning, algorithms like neural networks can take input and automatically produce an output. For example, a computer vision model can take an image of an animal and classify it as a cat or dog. How exactly an ML model achieves this depends on its learning paradigm, which can be supervised, unsupervised, or reinforcement learning.
In supervised learning, researchers know the inputs and their corresponding outputs but might need to learn the relationship between them. For example, what makes a dog in an image a dog and a cat an image of a cat in mathematical and computer terms? How can a machine learning algorithm take pixels of a dog or a cat and produce the corresponding correct prediction? Supervised machine learning algorithms can “find” the connection between inputs and outputs to identify and classify objects, predict changes in financial markets, or translate text from one language to another.
In unsupervised learning, the algorithm only has access to inputs – it’s given no associated outputs from which to learn a relationship. Instead, unsupervised algorithms are tasked to find some inherent structure or patterns in the data. For example, an unsupervised ML algorithm could take customer data and develop distinct clusters of people that may correspond to people who like action films and comedy films.
Finally, reinforcement learning aims to train an agent to perform specific tasks, like playing Go or passing through an obstacle course. The agent learns through a system of rewards and punishments where desirable actions lead to “rewards” and undesirable actions lead to “punishment. “With trial and error and a correctly set environment, the agent can eventually learn to perform its task.
All these use cases and ML methodologies share one key feature – data is known, whereas the model itself is unknown. Machine learning algorithms are essentially complex mathematical functions that can learn a mapping between an input and a corresponding output (which may or may not be known in advance). This situation is unlike simulation modeling, where the model is known, the inputs are assumed, and the outputs are unknown.
How Machine Learning May be Combined with Simulation
Now, how exactly can machine learning and simulation be combined with each other (von Rueden, et al., 2020)?
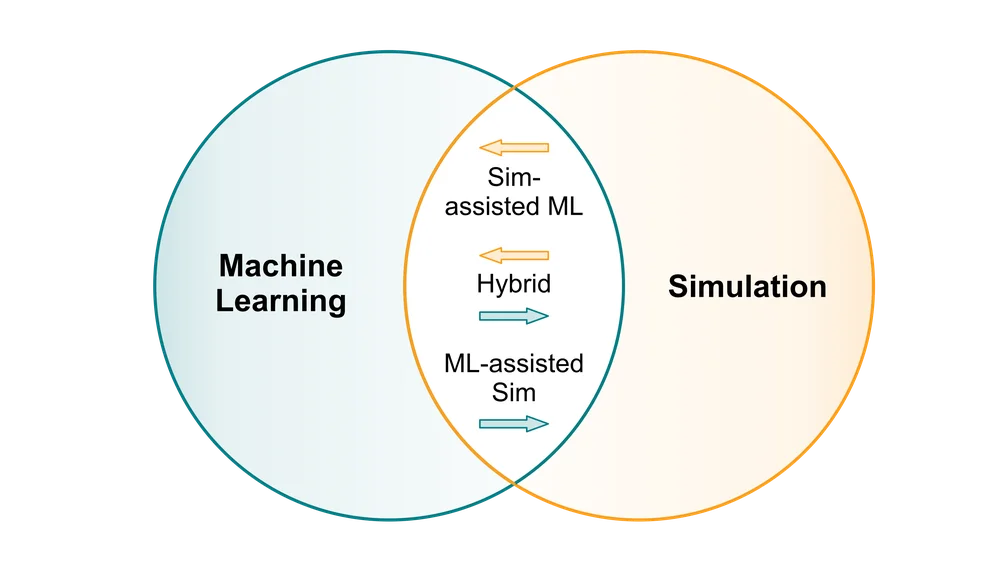
The answer is that it depends on the goal of the project. Simulation can be integrated into a machine learning pipeline or placed before or after. The same goes for simulation. Additionally, machine learning and simulation can have varying degrees of presence in a project, depending on the project’s challenges and objectives.
In broad terms, there are two combinations of ML and simulation – simulation-assisted machine learning and machine learning-assisted simulation. Let’s take a look at these two modes of operation below.
Simulation-Assisted Machine Learning
In simulation-assisted machine learning, machine learning takes on most of the heavy lifting. In essence, simulation-assisted machine learning performs tasks inherent to machine learning, like object classification, detection, or pattern extraction, but with some extra help from simulation. Von Rueden, et al., (2020, p. 6) describe the process framework for simulation-assisted machine learning:
“Simulations, in particular the simulation results, can be generally integrated into the four different components of machine learning. …The simulation results can be used to
a) augment the training data,
b) define parts of the hypothesis set in the form of empirical functions,
c) steer the training algorithm in generative adversarial networks, or
d) verify the final hypothesis against scientific consistency.”
Here are four prominent areas where simulation can help dramatically improve machine learning pipelines.
- Data augmentation. Simulations can serve as an extra source of data for machine learning. Simulation as a data source is particularly prominent in reinforcement learning and autonomous driving, where an ML agent is placed in a simulated environment where it can learn the relationship between millions of actions and their outcomes. The role of simulation for data augmentation is invaluable, though only some ML models or tasks can benefit from simulation-generated synthetic data.
- Support of ML models through empirical functions. Simulations may be integrated into ML models as solvers or through deduced functions that compactly describe the simulation model. Via such integration, simulation can provide contextual information that might help the ML model perform its task better.
- Constraint-based learning: Black-box simulators can automatically learn constraints (Ren, et al., 2018) for training generative adversarial networks (GANs). Setting constraints manually requires significant expertise and manual tweaking, which requires time and money. Adversarial constraint learning via simulation can help GANs learn constraints on their own. For example, this technique could be applied in pose estimation, where a GAN could use motion capture data and videos to learn the rules of joint movements. Constraint-based learning could also benefit healthcare (Mišić, et al., 2021), where resource limitations and costs can significantly affect patient care.
- Final hypothesis verification: Simulation can be used to verify the viability of the hypothesis learned by an ML algorithm. For example, for an ML model that came up with a novel material, simulation can be used to verify that the material can be built in the real world and is superior to currently available analogs.
Machine Learning-Assisted Simulation
The primary goal of the project in machine learning-assisted simulation is to identify how a system responds to specific inputs. Machine learning is a secondary toolset in such projects, aiming only to support and augment results achieved in simulation. Von Rueden, et al., (2020, p. 8) describe the process framework for ML-assisted Simulation:
“Machine learning techniques, in particular the final hypothesis, can be used in different simulation components. Exemplary use cases for machine learning models in simulation are
a) model order reduction and the development of surrogate models that offer approximate but simpler solutions,
b) the automated inference of an intelligent choice of input parameters for a next simulation run,
c) a partly trainable solver for differential equations, or
d) the identification of patterns in simulation results for scientific discovery.”
Below are four applications where machine learning can help researchers improve simulation results.
- Development of lighter surrogate models. After a simulation model is developed, researchers can use machine learning to obtain a more lightweight model that could approximate similar results but much faster and with much less computing overhead. This outcome is possible because machine learning algorithms, especially neural networks, can theoretically approximate any mathematical function, and simulation models are at a high level.
- Automated selection of input parameters for the next run. Researchers can use machine learning to detect patterns in how parameter changes affect simulation results. These patterns can reduce the time spent on the analysis of simulation parameters, allowing researchers to start simulating quicker and with a more intricate understanding of how different parameters may impact the results.
- Partly trainable solver for differential equations. Machine learning models might be used to infer solutions to partial differential equations (Raissi, et al., 2017) – a property that could be used in simulation to accelerate computation. Rather than directly computing the solution, machine learning could provide a faster way of solving numerical tasks approximately but with high accuracy.
- Pattern finding in simulation results. Machine learning could be used after simulation to help developers find hidden patterns or trends in simulation outputs. These outcomes could be invaluable from a research standpoint because machine learning models can learn representations and find patterns across vast volumes of data – something human researchers would never be able to do.
Next Steps
Simulation and machine learning are compelling tools even when used in isolation. However, by sticking only to one or the other, researchers might leave many extra insights on the table. With machine learning, researchers can detect additional patterns in simulation results, while with simulation, machine learning can get access to more data and added insight into the constraints of the model it’s trying to learn.
Thus, machine learning and simulation can be challenging to combine. Each field requires niche expertise and knowledge, and machine learning can be highly resource-intensive. Simulation has its own difficulties –it requires a deep understanding of the real-world process researchers attempt to model. Therefore, engineers must combine ML and simulation carefully to ensure they can meet their goals within a reasonable budget.
References:
Mišić, V. V., Rajaram, K., & Gabel, E. (2021). A simulation-based evaluation of machine learning models for clinical decision support: application and analysis using hospital readmission. NPJ Digital Medicine, 4(1), 98. https://www.nature.com/articles/s41746-021-00468-7
Raissi, M., Perdikaris, P., & Karniadakis, G. E. (2017). Physics informed deep learning (Part 1): Data-driven solutions of nonlinear partial differential equations. arXiv preprint arXiv:1711.10561. http://arxiv.org/abs/1711.10561
Ren, H., Stewart, R., Song, J., Kuleshov, V., Ermon, S.(2018). Adversarial constraint learning for structured prediction. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (IJCAI). AAAI Press. https://arxiv.org/pdf/1805.10561
von Rueden, L., Mayer, S., Sifa, R., Bauckhage, C., & Garcke, J. (2020). Combining machine learning and simulation to a hybrid modelling approach: Current and future directions. In Proceedings of the 18th International Symposium on Intelligent Data Analysis, (IDA 2020): Advances in Intelligent Data Analysis XVIII. Konstanz, Germany, April 27–29, (548-560). Springer.


